My Dad passed away at the start of 2022, and my Mom decided to sell the house shortly after. I was on the East Coast for work, so I stopped by before heading home and spent about six hours going through my childhood bedroom closet, making quick decisions about what could fit into the three oddly shaped boxes I was shipping back to LA.
They were oddly shaped because I had already made the correct adult decision to prioritize two guitars.
When I got to the comic books I had not looked at in more than 20 years, I started shoving stacks into whatever empty space was left. In retrospect, this was not archival best practice. I had no real idea what issues I had, what condition they were in, or whether I was preserving anything coherent. I just knew I wanted them.
A week or two later, I had a stack of old comics sitting in my house and no real system for them.
Sentiment got the books into the boxes. Maintenance was a different problem.
Rediscovering the collection
I did what any reasonable person would do and opened a spreadsheet. Titles in one column. Issue numbers in another. Maybe a note about condition if I was feeling ambitious. About 30 minutes in, the whole thing already felt like a punishment I had designed for myself.
Then I found CovrPrice, which was immediately better than my sad little spreadsheet. I could see cover art, group issues by title, sort by release date, track estimated values, and generally treat the collection like an actual collection instead of a list of things I half-remembered owning.
CovrPrice did one important thing right: it made the collection visible again. That mattered. It also got me back into collecting. Three years later, I still visit MidTownComics.com religiously, buying new releases and hunting down issues I missed as a kid.
That is the nice version of the story.
The practical version is that a collection is easy to own and hard to maintain. A collection is only useful if the inventory stays current. The second logging new books feels like a chore, the archive starts lying to you.
The maintenance problem
A couple months ago, I got an email from CovrPrice saying my yearly subscription price was going up by 50%. I understand that running a web app is not cheap, and I am not offended by software costing money. Good tools should cost money. People should be paid.
But once I was using CovrPrice every week, the friction became impossible to ignore. It was slow. It was cumbersome. It moved like a WordPress site that had accumulated too many plugins and too many page loads between me and the thing I was trying to do.
The real problem was not storing comics. It was maintaining the state of the collection without making myself hate the process.
Adding new purchases took too long. Search, click, wait, add, wait, confirm, wait, repeat. Forms loaded slowly. Pages loaded slowly. The interface made small updates feel expensive. That kind of friction is not neutral. It changes behavior.
Instead of logging five new books when they arrived, I would put them aside. Then there would be 12. Then 20. Then I would have a small shame stack next to my desk, which is not a collection management system no matter how generously you describe it.
Subscriptions are fine until the rented tool stops matching the value. Hosted software is fine until the workflow belongs more to the product than to you. At that point, you either accept the mismatch, stop maintaining the archive, or build something that fits.
Building the tool around the habit
Around the same time, a few things converged. I had been getting slowly addicted to what I call “vibe-coding” with AI assistants like bolt.new. We went on vacation for two weeks in the South of France, where I naturally spent too much time thinking about side projects. And while we were there, bolt.new had some kind of free tokens weekend that made experimentation feel cheap enough to be dangerous.
I have a love/hate relationship with tools like that. They are very good at starting projects and getting you 80% of the way there. Then, eventually, they can burn tokens in circular bug-fix loops until you have to take the wheel and rescue the code yourself.
AI made it easier to test the shape of the app quickly, but the useful part was not the magic. The useful part was having a real workflow to judge against. The reason the AI-assisted build worked at all is that the problem was not abstract. I had the books, the pain point, the fields, the habits, and the failure mode sitting in front of me.
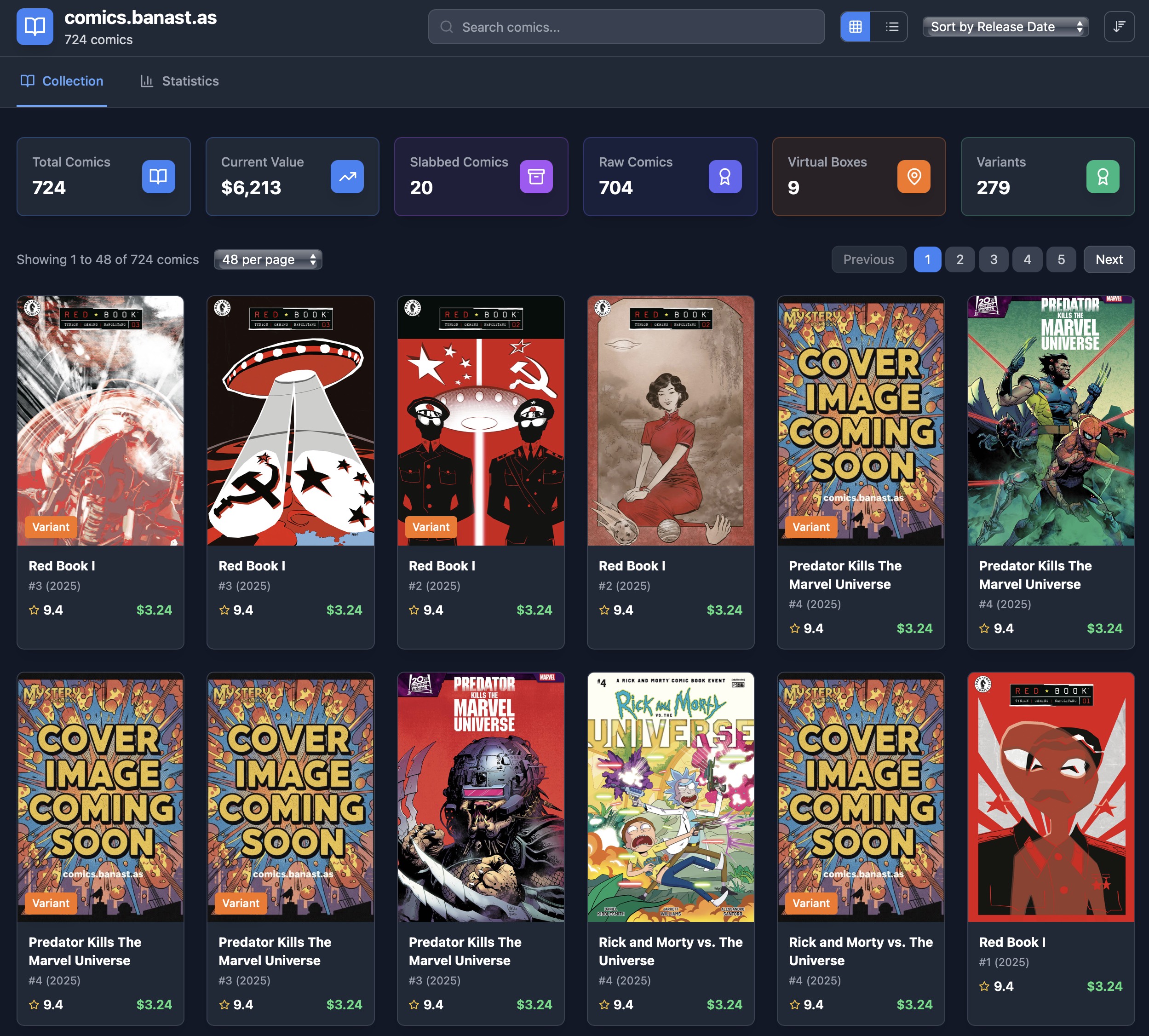
So I started building a personal, self-hosted comic collection tracker. Not a CovrPrice clone. Not a startup. Not a grand platform. A tool for the way I actually maintain this archive.
The app tracks titles, issue numbers, variants, cover images, condition, slabbed versus raw books, current values, and where things live in the collection. It gives me search, sorting, basic stats, and a faster add flow. It is built around the maintenance habit, not around the fantasy that someday I will sit down and lovingly enter metadata for an entire afternoon.
I built it with React, TypeScript, and Tailwind CSS. I also added a simple n8n workflow that updates the site’s main JSON file whenever I add new purchases to a Google Sheet. The next step is probably triggering that automatically from email order receipts from places like MidTown Comics, because that is where the workflow actually starts.
The value-tracking part is intentionally modest. I list current values for each comic, but I do not have it tied into a pricing system. I experimented with pulling spot averages from eBay listings, but exact issue matching, variants, and condition made that messy fast. It would be interesting to solve eventually, but it is not the point. Organization matters more to me than pretending I have built a tiny commodities desk for Predator variants.
Once I had the build stable enough for my own use, I made the repo public and released it as open source: github.com/banastas/comics.banast.as
Why personal archives need personal tools
This is the boring part of personal infrastructure that matters. The archive is not the folder, the shelf, the database, or the domain. The archive is the habit that keeps those things accurate.
If the tool makes the habit harder, the archive decays. If the tool makes the habit easier, the archive compounds.
That is why this belongs in the same family as the photography workflow posts. It is not really about the camera or the comics or the app. It is about maintaining a system long enough that it can still be useful later. Workflows decay unless they are maintained, and the easiest way to stop maintaining one is to make the next update annoying.
It is also why this now sits next to the same argument I make in Build on Your Own Land: the canonical version of something you care about should not depend entirely on someone else’s interface.
Building your own tool is not always efficient. Sometimes it is a ridiculous use of time. Sometimes the mature commercial product is better, cheaper, safer, and absolutely the right answer. I still use plenty of rented tools because I enjoy having a life.
But personal archives are strange. They carry memory, taste, money, metadata, physical storage, and years of tiny decisions. A comic collection is not just a pile of books. It is a memory system, an inventory problem, a data model, and a maintenance habit. The tool has to make the habit easier, or the archive quietly falls apart.
Open sourcing the app does not make it universally useful. It makes it inspectable. It makes it reusable if someone has a similar itch. It means the thing I built for my own collection is not trapped inside my own private setup. That is enough.
The comics were the sentimental part. The app is the maintenance part.
That distinction matters. A personal archive is not preserved by caring about it once. It is preserved by making the next update easy enough that you actually do it.
That was the real project.
Not replacing CovrPrice.
Not proving that AI can make an app.
Building a tool small enough, specific enough, and owned enough that the collection has a chance to stay alive.